计算字符串匹配度
题目介绍
BLEU是机器翻译任务中常用来评估模型生成的句子(candidate)和实际句子(reference)的匹配度的指标。常用计算公式为:
$$ \mathrm{BLEU} = \mathrm{BP} \times \mathrm{e} ^ {\sum _{n = 1} ^ N W_n \times \log_2 P_n} $$
现对其计算过程做一定简化和改动,请务必按以下步骤计算:
①从标准输入中依次读入权重$W_1、W_2、W_3、W_4$和字符串candidate、字符串reference。
②计算长度惩罚项BP:
$$ \mathrm{BP}= \begin{cases} 1, ~~~~&l_c \gt l_r \\ e^{1-\frac{l_r}{l_c}}, ~~~~&l_c \le l_r \end{cases} $$
其中,$l_c$为candidate长度,$l_r$为reference长度。
③计算$P_n$,其计算方式为:
I.以candidate的第一个字符为起点。
II.以包含起点在内的连续的n个字符作为候选子串,尝试在reference中匹配,若匹配到该子串,则reference中的该子串之后不再参与匹配,并以candidate中该候选子串的最后一个字符的下一个字符为新的起点;若未匹配到,则以起点的下一个字符为新的起点。如果candidate中以新起点为起始字符的任意连续子串长度均小于n,则跳到步骤III,否则重复步骤II。
III.计算整个过程中的命中率,其计算方式为:$\frac{\text{匹配成功的次数}}{\text{尝试匹配的次数}}$。
④计算BLEU,其计算方式为:
$$ \mathrm{BLEU} = \mathrm{BP} \times \mathrm{e} ^ {\sum _{n = 1} ^ 4 W_n \times \log_2 P_n} $$
注:①若恰好匹配完candidate中所有字符,则新的起点为'\0',此时以新起点为起始字符的子串的长度为0。
②在reference中删去某子串后,该子串前面一个字符和后面一个字符之间依然不连续。
③若对步骤存在疑惑,可结合样例说明进行理解。
④为了简化操作方便理解,本题对BLEU的计算过程进行了魔改,对原算法感兴趣的同学可以再多做了解。
输入格式
三行输入。
第一行输入字符串candidate。
第二行输入字符串reference。
第三行输入4个以空格分隔的浮点数,分别为权重$W_1、W_2、W_3、W_4$ 。
输出格式
输出1个浮点数,为candidate和reference的BLEU计算结果,保留4位小数。
输入样例1
I have a pen.
I have an apple.
0.25 0.25 0.25 0.25输出样例1
0.3065输入样例2
This is a test, haha.
This is not a test.
0.2 0.3 0.2 0.3输出样例2
0.3283数据范围
字符串长度均不超过10000,其中只包含可见字符。
样例1说明
以$P_2$为例:
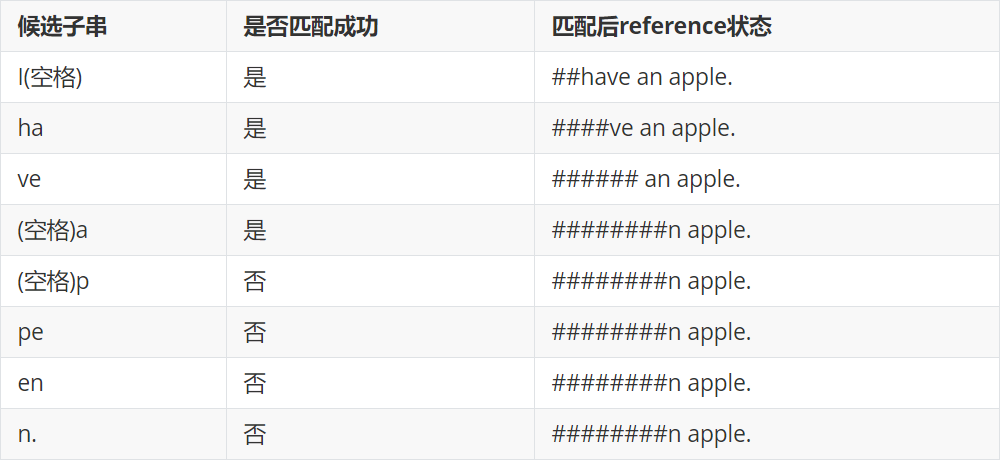
故$P_2 = \frac{4}{8}$ = 0.5。
Author:曹博文